MediaPipe tutorial: Find memes matching your facial expression 😮
Or: How to use MediaPipe from Swift
Originally posted on Jun 5, 2020 as part of a collaboration between Google and Powder.gg. Some links were updated.
A post by Pierre Fenoll, Senior Lead Back-End Engineer at Powder.gg
Introduction
Powder.gg is a startup located in the beautiful district of Marais in Paris. We are working hard to help gamers edit their highlights with machine learning on mobile. AI, memes, sound and visual effects make up the toolkit we aim to provide to people all around the world to help them understand each other better. Our team has been using MediaPipe extensively to create our machine learning enabled video editing app for gamers.We created this tutorial to show how you can use MediaPipe to create your next ML enabled app.
Goals and requirements
Say you’re chatting on your phone with some friends. Your friend, Astrid wrote something amusing and you wanted to post a funny image related to hers . There’s this picture you really want to post but it’s not on your phone and now you’re just trying different words in your search engine of choice without any success. This image is so clear in your mind, the words to look it up just don’t come out right somehow. If only you could just make the same hilarious face to your phone and it would find it for you!
Let’s build a computer vision pipeline that compares a face from a phone’s front camera (for instance) with a collection of images containing at least a face: a collection of Internet memes.
Here’s the app we’re building.
Figure 1: Demo of the end result iOS app
Machine Learning model for our pipeline
We need a machine learning model that can determine how similar 2 images with facial expressions are. The emotions/facial expression recognition module we use is based on a 2019 paper published by Raviteja Vemulapalli and Aseem Agarwala, from Google AI, titled A Compact Embedding for Facial Expression Similarity. At Powder, we re-implemented the approach described in that paper. We then improved on this approach by using knowledge distillation, a technique whereby an often smaller student network is trained to mimic the predictions made by a teacher network. We have found that using knowledge distillation leads to an even more accurate model. We also incorporated millions of additional unlabelled images in the knowledge distillation process, and found this improved performance even further.
Specifically, the original Google paper reported 81.8% “triplet prediction accuracy” of their model on their face triplets dataset. Our re-implementation of this approach yielded closer to 79% accuracy, with the drop likely being due to our not-quite-complete reproduction of their dataset (due to source images being removed from Flickr). Using knowledge distillation with additional unlabelled data, we were then able to improve this score to 85%.
Our initial training pipeline was written in Pytorch. Considering that we want to create our inference pipelines using MediaPipe that has out of the box support for TensorFlow and TFlite models. We quickly migrated our training pipeline from Pytorch to TensorFlow. For this tutorial, we are releasing publicly a distilled MobileNetV2 version of our TFlite model with accuracy closer to 75%. This model should be sufficient to demonstrate the capabilities of MediaPipe and to have a bit of fun matching memes to faces.
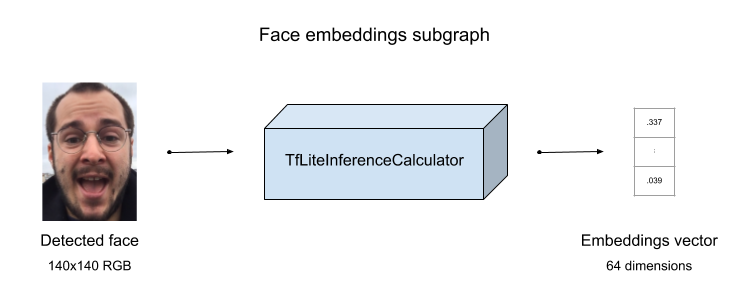
Figure 2: Block diagram illustrating what model does images -> embedding
For a quick introduction into MediaPipe
- Hello World examples: Android iOS Python Javascript C++
- Video from MediaPipe Seattle 2020 meet-up
Prototyping the pipeline on the desktop
In order to prototype the inference pipeline using MediaPipe that will find memes that have similar facial expressions from a video, we started out building the desktop prototype as iteration can be much faster than with a mobile in the loop. After the desktop prototype, we can optimize for our main target platform: Apple iPhones. We start by creating a C++ demonstration program similar to the provided desktop examples and build our graphs from there.
Figure 3: Animated gif showing demo of the MediaPipe pipeline showing how we match facial expressions in a video to internet memes
Although it is possible to create a repository separate from MediaPipe (as demonstrated here), we prefer to develop our graphs and calculators in our own fork of the project. This way upgrading to the latest version of MediaPipe is just a git-rebase away.
To avoid potential conflicts with MediaPipe code we replicate the folder architecture under a subdirectory of mediapipe: graphs, calculators and the required BUILD files.
MediaPipe comes with many calculators that are documented, tested and sometimes optimized for multiple platforms so we try as much as possible to leverage them. When we really need to create new calculators we try to design them so that they can be reused in different graphs. For instance, we designed a calculator that displays its input stream to an OpenCV window and which closes on a key press. This way we can quickly plug into various parts of a pipeline and glance at the images streaming through.
MediaPipe Graph — Face Detection followed by Face embedding
We construct a graph that finds faces in a video, takes the first detection then extracts a 64-dimensions vector describing that face. Finally it goes through a custom-made calculator that compares these embeddings against a large set of vector-images pairs and sorts the top 3 results using Euclidean distance.
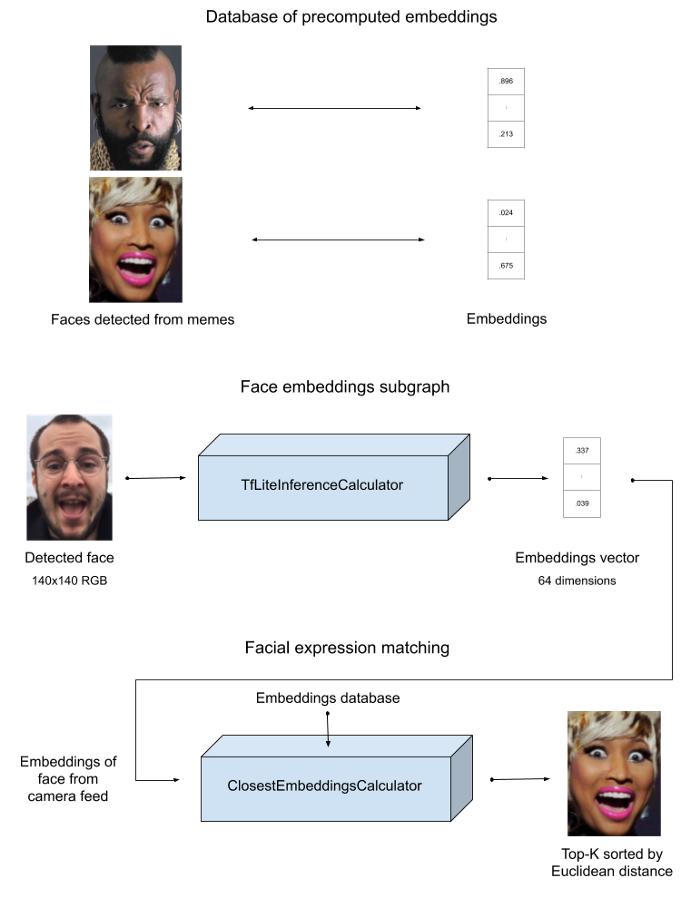
Figure 4: The algorithm behind FacialSearch
Face detection is performed with MediaPipe’s own SSD based selfie face detector graph. We turned the gist of it into a subgraph so our graph can easily link against it as well as some of our other graphs. Subgraphs are great for reusability and can be thought of as modules. We tend to create one per model just for the benefit of encapsulation.
Embeddings are extracted within the FaceEmbeddingsSubgraph using our Tensorflow Lite model and streamed out as a vector of 64 floats. This subgraph takes care of resizing the input image and converting to and from Tensorflow tensors.
Then our ClosestEmbeddingsCalculator expects this vector, computes the distance to each vector in the embedded database and streams out the top matches as Classifications, with the distance as score. The database is loaded as a side packet and can be generated with the help of a Shell script. A sample database of around 400 entries is provided.
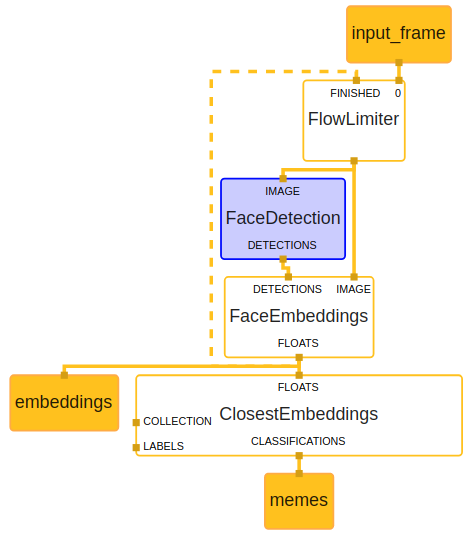
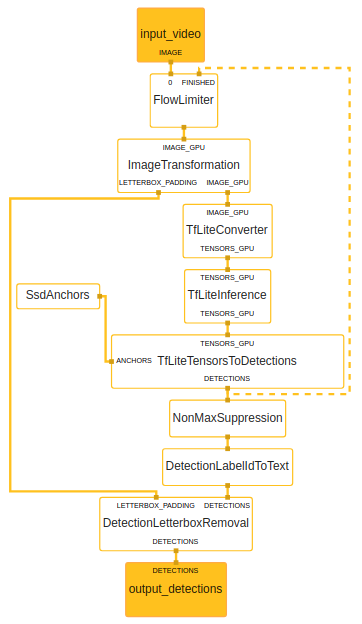
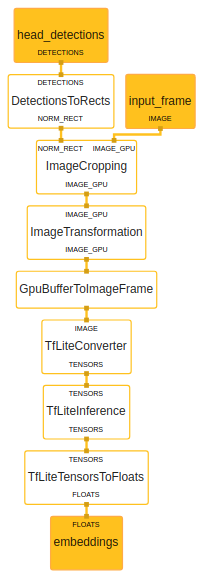
Figure 5. Left to right, top down: ① main graph ② FaceDetection subgraph ③ FaceEmbeddings subgraph
Issues we faced
You may have noticed in the above GPU FaceEmbeddingsSubgraph the use of the GpuBufferToImageFrame calculator. This moves an image from GPU to the host CPU. It turns out our model uses instructions that are not supported by the current version of the Tensorflow Lite GPU interpreter. Running it would always return the same values and output the following warnings when initializing the graph:
ERROR: Next operations are not supported by GPU delegate:
MAXIMUM: Operation is not supported.
MEAN: Operation is not supported.
First 0 operations will run on the GPU, and the remaining 81 on the CPU.
There are multiple ways to fix this:
- You can re-train your model such that the generated tflite file uses only supported operations.
- You can implement the operations in C++ and use MediaPipe’s TfLiteCustomOpResolverCalculator to provide them to the interpreter.
- If your model runs fine on CPU you can just make sure inference always runs on CPU by moving its inputs to CPU. Moving data from GPU to host CPU is however not free so inference should be a bit slower.
We opted for the simplest option for this tutorial as runtime costs appeared minimal. We may be providing a model that can run on GPU in the future.
Running on the desktop
First make sure the images of our database are on your system. These come from imgflip.com and were selected on the criterion that they contain at least one human face. There are mostly pictures but some drawings as well. Download them with:
python mediapipe/examples/facial_search/images/download_images.py
Then you are free to re-generate the embeddings data. This process uses our graph on the images we downloaded to extract a float vector per image. These are then written to a C++ header file to constitute the database. Keep in mind that there can be some differences in floating point precision from one platform to another so you might want to generate the embeddings on the targeted platform. Run:
./mediapipe/examples/facial_search/generate_header.sh \
mediapipe/examples/facial_search/images
Now run the demo on CPU with:
bazel run --platform_suffix=_cpu \
--copt=-fdiagnostics-color=always --run_under="cd $PWD && " \
-c opt --define MEDIAPIPE_DISABLE_GPU=1 \
mediapipe/examples/facial_search/desktop:facial_search \
-- \
--calculator_graph_config_file=mediapipe/examples/facial_search/graphs/facial_search_cpu.pbtxt \
--images_folder_path=mediapipe/examples/facial_search/images/
And run the demo on GPU with:
bazel run --platform_suffix=_gpu \
--copt=-fdiagnostics-color=always --run_under="cd $PWD && " \
-c opt --copt -DMESA_EGL_NO_X11_HEADERS --copt -DEGL_NO_X11 \
mediapipe/examples/facial_search/desktop:facial_search \
-- \
--calculator_graph_config_file=mediapipe/examples/facial_search/graphs/facial_search_gpu.pbtxt \
--images_folder_path=mediapipe/examples/facial_search/images/
Exit the program by pressing any key.
Going from desktop to app
Tulsi can be used to generate Xcode application projects and Bazel can be used to compile iOS apps from the command line. As iOS app developers we prefer to be able to import our graphs into our existing Xcode projects. We also plan to develop Android apps in the near future so we are betting on MediaPipe’s multiplatform support to reduce code duplication.
We designed an automated way to package our graphs as iOS frameworks. This runs as part of our Continuous Integration pipeline with macOS GitHub Actions and relies on Bazel and some scripting. Framework compilation and import being two separate steps, our mobile developers needn’t worry about the C++ and Objective-C part of the graphs and can build apps in Swift.
General steps
- First, clone our example code:
git clone --single-branch facial-search https://github.com/fenollp/mediapipe.git cd mediapipe - Create a new “Single View App” in Xcode, setting language to Swift
- Delete these files from the new project: (Move to Trash)
- AppDelegate.swift
- ViewController.swift
- Copy these files to your app from
mediapipe/examples/facial_search/ios/: (if asked, do not create a bridging header)- AppDelegate.swift
- Cameras.swift
- DotDot.swift
- FacialSearchViewController.swift
- Edit your app’s
Info.plist:- Create key
NSCameraUsageDescriptionwith value:This app uses the camera to demonstrate live video processing.
- Create key
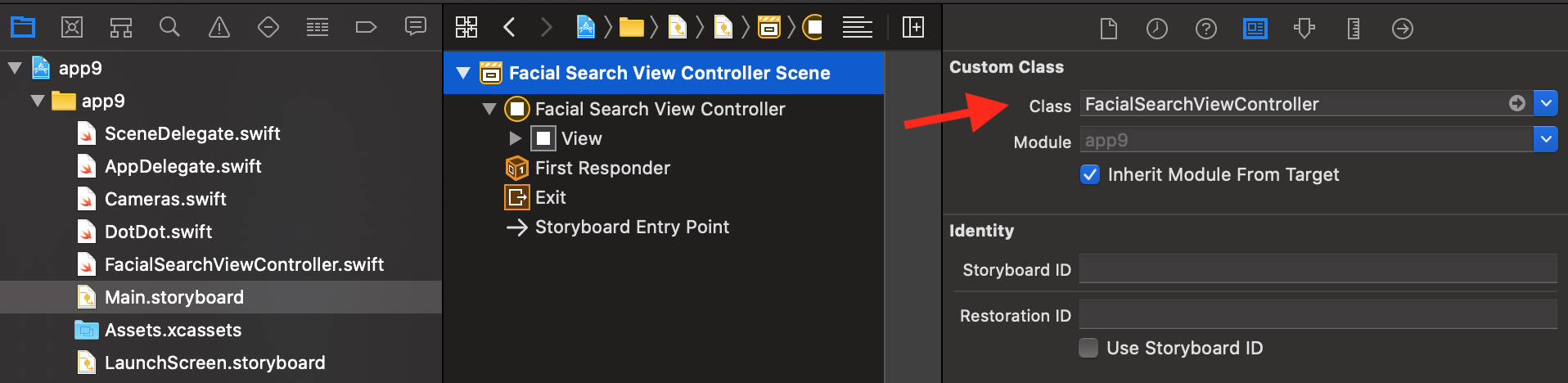
- Edit your
Main.storyboard’s custom class, setting it toFacialSearchViewController(in the Identity inspector) - Build the iOS framework with
bazel build --config=ios_arm64 \ --copt=-fembed-bitcode --apple_bitcode=embedded \ mediapipe/examples/facial_search/ios:FacialSearchSome linker warnings about global C++ symbols may appear.
The flags--copt=-fembed-bitcode --apple_bitcode=embeddedenable bitcode generation. - Patch the Bazel product so it can be imported properly:
./mediapipe/examples/facial_search/ios/patch_ios_framework.sh \ bazel-bin/mediapipe/examples/facial_search/ios/FacialSearch.zip ObjcppLib.hNote: append the contents of
FRAMEWORK_HEADERSseparated by spaces (here:ObjcppLib.h). - Open
bazel-bin/mediapipe/examples/facial_search/iosand drag and drop theFacialSearch.frameworkfolder into your app files- Copy items if needed > Finish
- Make sure the framework gets embedded into the app.
- In General > Frameworks, Libraries, and Embedded Content set
FacialSearch.frameworktoEmbed & Sign 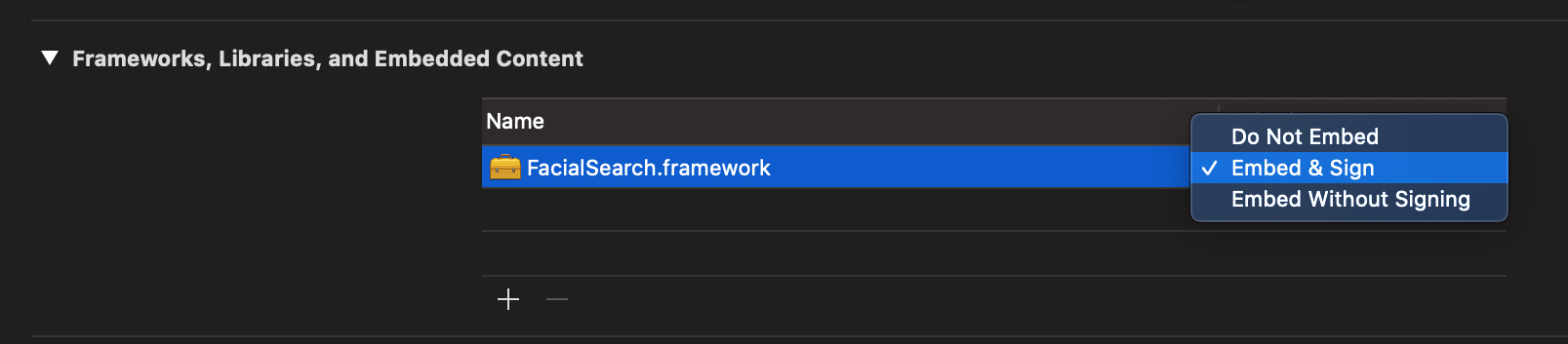
- In General > Frameworks, Libraries, and Embedded Content set
- Connect your device and run.
- Note the preprocessor statements at the top of
FacialSearchViewController.swift:
- Note the preprocessor statements at the top of
import AVFoundation
import SceneKit
import UIKit
#if canImport(FacialSearch)
// Either import standalone iOS framework...
import FacialSearch
func facialSearchBundle() -> Bundle {
return Bundle(for: FacialSearch.self)
}
#elseif canImport(mediapipe_examples_facial_search_ios_ObjcppLib)
// ...or import the ObjcppLib target linked using Bazel.
import mediapipe_examples_facial_search_ios_ObjcppLib
func facialSearchBundle() -> Bundle {
return Bundle.main
}
#endif
There are two ways you can import our framework:
- If it was imported using the above technique just use
import FacialSearch
- If however you used Tulsi or Bazel to build the app you will have to use the longer form that reflects the Bazel target of the library the framework provides
import mediapipe_examples_facial_search_ios_ObjcppLib
Why the need for patch_ios_framework.sh?
It turns out the Apple rules of Bazel do not yet generate importable iOS frameworks. This was just not the intended usage of ios_framework. There is however an open issue tracking the addition of this feature.
Our script is a temporary workaround that adds the umbrella header and modulemap that Bazel does not create. This lists the Objective-C headers of your framework as well as the iOS system libraries either your code or MediaPipe’s require to run.
Conclusion
We built a machine learning inference graph that uses two Tensorflow Lite models, one provided by the MediaPipe team and one we developed at Powder.gg. Then discussed using subgraphs and creating our own MediaPipe calculators. Finally we described how to bundle our graph into an iOS framework that can readily be imported into other Xcode projects.
Here’s a link to a GitHub repository with the code and assets mentioned in this post.
Here’s the corresponding pull request against upstream MediaPipe at Google.
We sincerely hope you liked this tutorial and that it will help you on your way to create applications with MediaPipe.